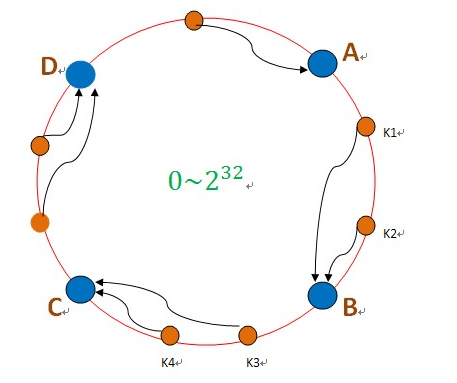
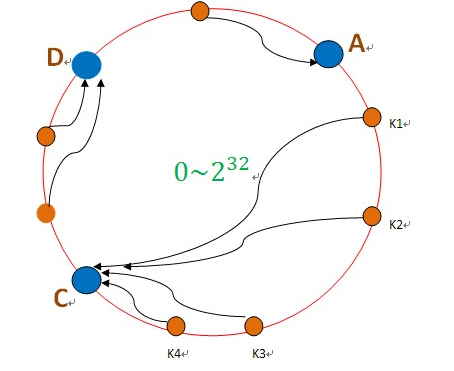
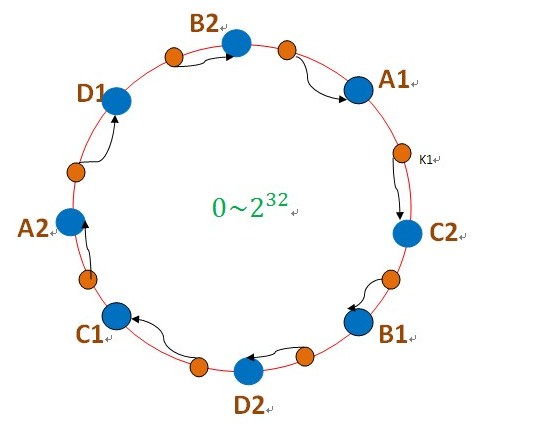
S类封装了机器节点的信息 ,如name、password、ip、port等
**/
public class Shard<S> {
private TreeMap<Long, S> nodes;
private List<S> shards;
private final int NODE_NUM = 100;
public Shard(List<S> shards) {
super();
this.shards = shards;
init();
}
private void init() {
nodes = new TreeMap<Long, S>();
for (int i = 0; i != shards.size(); ++i) {
final S shardInfo = shards.get(i);
for (int n = 0; n < NODE_NUM; n++)
nodes.put(hash("SHARD-" + i + "-NODE-" + n), shardInfo);
}
}
public S getShardInfo(String key) {
SortedMap<Long, S> tail = nodes.tailMap(hash(key));
if (tail.size() == 0) {
return nodes.get(nodes.firstKey());
}
return tail.get(tail.firstKey());
}
* MurMurHash算法,是非加密HASH算法,性能很高,
* 比传统的CRC32,MD5,SHA-1(这两个算法都是加密HASH算法,
* 复杂度本身就很高,带来的性能上的损害也不可避免)
* 等HASH算法要快很多,而且据说这个算法的碰撞率很低.
* http://murmurhash.googlepages.com/
*/
private Long hash(String key) {
ByteBuffer buf = ByteBuffer.wrap(key.getBytes());
int seed = 0x1234ABCD;
ByteOrder byteOrder = buf.order();
buf.order(ByteOrder.LITTLE_ENDIAN);
long m = 0xc6a4a7935bd1e995L;
int r = 47;
long h = seed ^ (buf.remaining() * m);
long k;
while (buf.remaining() >= 8) {
k = buf.getLong();
k *= m;
k ^= k >>> r;
k *= m;
h ^= k;
h *= m;
}
if (buf.remaining() > 0) {
ByteBuffer finish = ByteBuffer.allocate(8).order(
ByteOrder.LITTLE_ENDIAN);
finish.put(buf).rewind();
h ^= finish.getLong();
h *= m;
}
h ^= h >>> r;
h *= m;
h ^= h >>> r;
buf.order(byteOrder);
return h;
}
}